



I. Introduction▲
L'union entre les concepts d'objet et de rûˋpartition semble ûˆtre l'une des combinaisons gagnantes de la fin des annûˋes 1990, comme le fut û la fin des annûˋes 1980 la combinaison entre les interfaces graphiques et les bases de donnûˋes relationnelles qui conduisit au fameux modû´le client-serveur. Avec les objets rûˋpartis, un pas de plus est franchiô : il ne s'agit plus de systû´mes locaux et fermûˋs dans lesquels les rûÇles de client et de serveur sont ûˋtablis û l'avance, mais de systû´mes ouverts dans lesquels les objets, û la fois clients et serveurs, coopû´rent dans un monde dûˋmocratique û travers Internet. Les efforts dûˋployûˋs par l'industrie pour affiner les technologies orientûˋes objet et les rendre ûˋconomiquement et techniquement viables sont considûˋrables, et le danger pour des ûˋquipes de recherche universitaires est de se retrouver paradoxalement û la traûÛne. Malheureusement pour les utilisateurs des objets rûˋpartis, et pour les sociûˋtûˋs qui en font des bûˋnûˋfices, mais fort heureusement pour les chercheurs dans le domaine, l'union des concepts d'objet et de rûˋpartition, bien que consommûˋe, est semûˋe d'embû£ches. Des problû´mes fondamentaux sont encore û rûˋsoudre, loin des batailles stratûˋgiques que se livrent DCOM, CORBA, Java RMI et ONE.
II. Des mots magiques▲
Java RMI, ONE, CORBA, et DCOM sont des acronymes dont vous avez probablement entendu parler, qui vous ont peut-ûˆtre fait peur, ou du moins vous ont un peu dûˋpassûˋ. Vous avez peut-ûˆtre fait semblant d'en comprendre certains, ou mûˆme pire, vous les avez utilisûˋs pour avoir l'air dans le coup.
Ces mots magiques ont deux points communs. Le premier est qu'ils sont tous considûˋrûˋs comme trû´s branchûˋs, et par consûˋquent sont particuliû´rement apprûˋciûˋs dans les rûˋunions au sommet sur les nouvelles technologies informatiques. Je me souviens d'un professeur d'informatique qui, au sujet de la maniû´re d'ûˆtre un bon ingûˋnieur commercial, nous conseillait d'utiliser beaucoup d'acronymes, et de souvent rûˋpûˋter ceux que nos interlocuteurs semblaient ne pas comprendre. Cela, disait-il, permet d'ûˋtablir un rapport de force en notre faveur, et de faciliter les nûˋgociations par la suite.
Le deuxiû´me point commun de ces acronymes est que tous sont les fruits du mûˆme mariage, d'un grand mariage, d'un mariage comme on en voit rarement. Il s'agit du mariage de deux technologies, presque aussi vieilles que l'informatique, mais chacune particuliû´rement en vogue ces derniers temps: la programmation par objets et les systû´mes rûˋpartis. On peut se demander si un tel mariage n'est pas seulement un mariage de raison, permettant aux acteurs industriels dûˋveloppant chacune des deux technologies d'ûˋtendre un peu plus leur champ d'action. Un peu comme lorsque l'on apprend que Michael Jackson ûˋpouse Lisa Marie Presley, et que l'on se demande si le premier ne veut tout simplement pas se faire adopter par un public nostalgique du vrai rock et plus regardant sur certaines méurs, et si la seconde n'aimerait pas simplement entrer par la grande porte dans le monde du show-business.
Il y a trû´s probablement du vrai dans un scûˋnario arrangûˋ, mais au-delû du mariage de raison, il y a une complûˋmentaritûˋ indûˋniable entre les deux partenaires, en tout cas en ce qui concerne les concepts d'objet et de rûˋpartition.
III. Il ûˋtait une fois un langage de programmation▲
Le premier langage de programmation par objets, Simula, a ûˋtûˋ dûˋfini en 1965 par Ole-Johan Dahl et Kristen Nygaard en Norvû´ge. Il avait pour objectif les applications de simulation, mais ses concepteurs rûˋalisû´rent que les concepts sous-jacents du langage pouvaient s'appliquer û d'autres types d'applications. Ils dûˋveloppû´rent alors le successeur de Simula, Simula 67, comme une extension du langage Algol 60, en y rajoutant les concepts d'encapsulation et d'hûˋritage, û travers les mûˋcanismes de classes et de sous-classes. Le concept d'encapsulation permettant de rûˋunir des donnûˋes et des procûˋdures dans une mûˆme entitûˋ anthropomorphique, appelûˋe objet, et de sûˋparer les interfaces des mises en éuvre, s'avûˋra particuliû´rement utile pour concevoir les composants d'un programme de maniû´re modulaire, et de s'abstraire des dûˋtails de leur mise en éuvre. Ce concept inspira C.A.R. Hoare en 1972 dans la construction de types abstraits de donnûˋes, puis un peu plus tard en 1977, Barbara Liskov et Alain Snyder dans la conception du langage CLU. Par ailleurs, le concept d'hûˋritage, permettant d'automatiser le procûˋdûˋ de rûˋutilisation du code par spûˋcialisation, s'avûˋra particuliû´rement utile pour faciliter le prototypage et rendre plus lisibles les programmes. La puissance de ce concept fut dûˋmontrûˋe û travers le langage Smalltalk, dûˋveloppûˋ par Alain Kay et Adû´le Goldberg au dûˋbut des annûˋes 80 chez Xerox, û travers la bibliothû´que des composants de l'interface graphique de dûˋveloppement. Pour la petite histoire, on raconte que des ingûˋnieurs de chez Apple, alors qu'ils dûˋveloppaient l'interface graphique du systû´me Mac OS, rendirent souvent visite û leurs voisins de Xerox. On sait par la suite que le fameux Windows95 s'inspira quelque peu (beaucoup) de cette interface graphique.
La dûˋnomination langage de programmation orientûˋ objet, ou plus simplement langages û objets, fut attribuûˋe aux langages, tels que Simula, Smalltalk et Eiffel, qui offraient des mûˋcanismes de construction de classes et de sous-classes. Pendant longtemps, ces langages furent considûˋrûˋs comme des jouets pour les universitaires, ou au mieux comme des outils de composition de fenûˆtres en couleur. La raison invoquûˋe ûˋtait la lenteur d'exûˋcution des programmes. Le succû´s industriel de C++, un peu plus pragmatique et plus proche des machines que ses prûˋdûˋcesseurs, mit fin û ce tabou. On connaûÛt la suite de l'histoire avec un fameux cafûˋ (1).
IV. Le grand mariage▲
IV-A. Dûˋjû û l'ûˋpoque▲
Le premier langage û objets, Simula 67, permettait dûˋjû de programmer des applications rûˋparties (du moins logiquement). GrûÂce û la notion de coroutine de Simula, le programmeur pouvait ûˋcrire des activitûˋs indûˋpendantes, et les faire exûˋcuter de maniû´re concurrente. Quoi de plus naturel en fait puisque, d'une part Simula ûˋtait destinûˋ û des applications de simulation, en particulier de processus industriels oû¿ certaines activitûˋs se dûˋroulent en parallû´le, et d'autre part, le concept d'objet ûˋtait destinûˋ û modûˋliser des entitûˋs du monde rûˋel, souvent autonomes. Du fait probablement du poids culturel de la programmation sûˋquentielle, et des limitations technologiques de la vitesse de communication en rûˋseau, l'aspect rûˋpartition des langages û objets fut mis en veilleuse. Pas complû´tement nûˋanmoins, car dans les annûˋes 80, au MIT par exemple, Carl Hewit et Gul Agha s'amusaient avec des objets actifs pour modûˋliser des piû´ces de thûˋûÂtre (les fameux acteurs), et Barbara Liskov proposait une extension rûˋpartie du langage CLU, appelûˋe ARGUS, pour permettre û des objets de communiquer û travers des machines distantes (les fameux objets gardiens). Un peu plus û l'Ouest, û l'Universitûˋ de Washington, Andrew Black proposait un systû´me, baptisûˋ Emerald, qui permettait de rendre mobiles des objets en les faisant voyager d'une machine û une autre.
IV-B. Tout s'est ensuite passûˋ trû´s vite▲
Depuis, la vitesse de communication entre machines est devenue de plus en plus rapide grûÂce aux progrû´s technologiques des rûˋseaux. Par ailleurs, l'intûˋrûˆt de la rûˋpartition est devenu fondamental. Des applications rûˋparties, telles que le travail coopûˋratif et le commerce ûˋlectronique, sont devenues û la mode. De plus, on s'est rendu compte que la rûˋpartition permet de tolûˋrer les dûˋfaillances, de rûˋpartir les charges et de partager les ressources l'un des programmes rûˋpartis les plus utilisûˋs est celui qui permet le partage d'une imprimante par plusieurs utilisateurs. Bref, on s'est rendu compte que la rûˋpartition permet de laver encore plus blanc.
La premiû´re phase dans la crûˋation d'architectures rûˋparties a consistûˋ û permettre û des machines, appelûˋes serveurs, d'accomplir des tûÂches spûˋcifiques pour le compte d'autres machines, aux capacitûˋs plus restreintes, appelûˋes clients. Ce type d'architecture ûˋtait particuliû´rement adaptûˋ û des rûˋseaux locaux, regroupant un nombre limitûˋ de machines. La seconde phase, plus ambitieuse, a consistûˋ û permettre û des machines de coopûˋrer dans un monde plus dûˋmocratique. On parle encore de clients et de serveurs, mais un serveur peut se retrouver lui-mûˆme client et vice-versa. L'objectif est ici de concevoir des applications mettant en éuvre plusieurs rûˋseaux locaux, dans une structure ouverte, oû¿ des machines peuvent se connecter pendant l'exûˋcution d'une application.
Pour d'une part mieux structurer et faciliter la maintenance des programmes rûˋpartis, considûˋrûˋs û juste titre comme particuliû´rement complexes, et d'autre part mieux modûˋliser l'autonomie et la communication entre composants rûˋpartis, l'union entre les concepts d'objet et de rûˋpartition ûˋtait devenue inûˋluctable. Il y a eu deux mariagesô : un mariage suivant une approche appliquûˋe, et un deuxiû´me suivant une approche intûˋgrûˋe.
IV-C. Le mariage par l'application▲
Cette approche a consistûˋ û appliquer les concepts de la programmation par objets, en tant que tels, pour structurer les systû´mes informatiques rûˋpartis. Les diffûˋrents composants de ces systû´mes, tels que les processus, les sûˋmaphores, les transactions, etc., sont reprûˋsentûˋs par des classes spûˋcifiques d'objets. On parle alors de services rûˋpartis. La programmation reste sûˋquentielle et on procû´de par extension des bibliothû´ques sûˋquentielles, en modûˋlisant les aspects relatifs û la rûˋpartition avec de nouvelles classes. L'objectif est en particulier d'apporter une certaine gûˋnûˋricitûˋ aux architectures. Le programmeur peut alors appliquer le concept d'encapsulation, pour modifier certains composants du systû´me de maniû´re modulaire, en fonction d'une application ou d'une machine particuliû´re, puis appliquer le concept d'hûˋritage, pour spûˋcialiser certains composants û travers des nouvelles classes. La figure 1 reprûˋsente des classes modûˋlisant des concepts de rûˋpartition tels que les transactions, les transactions emboûÛtûˋes, les processus, les sûˋmaphores, les verrous ou les moniteurs.
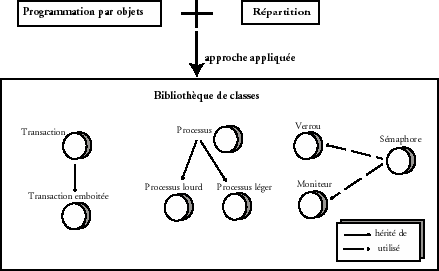
L'assemblage des diffûˋrentes classes est soit laissûˋ aux bons soins du programmeur, soit prûˋalablement rûˋalisûˋ par les concepteurs des classes. Dans le premier cas, on parle de boûÛte û outils, et le programme contrûÇle les connexions entre les classes, i.e., les communications entre les objets. Dans le second cas, le programmeur trouve une charpente prûˋalablement construite, suivant un motif bien rodûˋ (on parle respectivement de framework et de pattern). Sa tûÂche se rûˋduit dans ce cas û mettre en éuvre certaines opûˋrations appelûˋes û son insu lors de l'exûˋcution d'un programme rûˋparti (on parle de call back), suivant le principe de Hollywood, oû¿ l'on rûˋpond aux jeunes qui se prûˋsentent pour un premier rûÇle ô¨ô don't call us, we will call youô !ô ô£.
En rûˋsumûˋ, le mariage par application consiste û utiliser un langage et une mûˋthodologie de programmation û objets pour structurer un systû´me rûˋparti. En plus des objets sûˋquentiels d'une application, on trouve des objets permettant de reprûˋsenter les concepts de la rûˋpartition. Cela permet de bien structurer les mûˋcanismes de rûˋpartition, mais laisse le programmeur en charge de deux tûÂches distinctesô : d'une part la programmation des objets sûˋquentiels et centralisûˋs de l'application, et d'autre part la gestion de la rûˋpartition, ûˋgalement exprimûˋe û l'aide d'objets, mais pas les mûˆmesô !
IV-D. Le mariage par l'intûˋgration▲
Au lieu de laisser ces dimensions relativement orthogonales, l'approche intûˋgrûˋe vise justement û les fusionner, et û ûˋtendre les concepts fondateurs des objets en y intûˋgrant les concepts sous-jacents de la rûˋpartition. Plusieurs niveaux d'intûˋgration complûˋmentaires peuvent ûˆtre considûˋrûˋs.
IV-D-1. Invocation d'objets û distance▲
Du fait qu'un objet contient ses propres donnûˋes et opûˋrations, il constitue une unitûˋ indûˋpendante d'exûˋcution et de rûˋpartition (fig. 2).
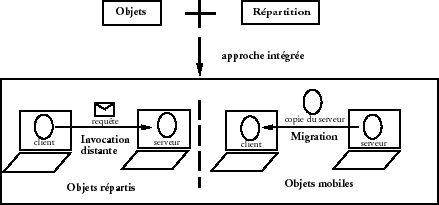
Cela permet de considûˋrer une application rûˋpartie comme un ensemble d'objets, chacun situûˋ sur une machine distincte. La mûˋtaphore de la communication par ô¨ô envoi de messageô ô£, dans Smalltalk par exemple, prend ainsi tout son sens lorsqu'il s'agit d'objets situûˋs sur des machines diffûˋrentes. On parle d'invocation d'objet û distance, et de nombreux systû´mes assurent la transparence d'une telle invocationô : tout se passe comme si l'objet ûˋtait local. Pour prendre en compte l'inaccessibilitûˋ des objets, le systû´me Argus du MIT dans les annûˋes 80 permet par exemple d'associer des exceptions û chaque invocation. Si un objet est situûˋ sur une machine qui est inaccessible, û cause d'une panne du rûˋseau de communication ou du processeur de la machine, l'exception est dûˋclenchûˋe. Cela permet par exemple d'invoquer un autre objet û la place.
IV-D-2. Objets mobiles▲
L'autonomie des objets, en tant que capsules de donnûˋes et d'opûˋrations associûˋes, facilite la migration ûˋventuelle. Lorsqu'un objet client dûˋsire invoquer un objet serveur distant, plutûÇt qu'une invocation distante, la migration permet de dûˋplacer l'objet serveur (ou une copie de cet objet) chez le client (fig.2). Cela est particuliû´rement utile lorsque le client dûˋsire effectuer plusieurs opûˋrations sur un mûˆme serveur.
IV-D-3. Objets actifs▲
En intûˋgrant le concept de processus aux objets, ces derniers deviennent actifs. L'objet est alors dotûˋ d'une ressource de calcul, c'est-û -dire douûˋ d'activitûˋ propre. Le concept d'objet actif a eu beaucoup de succû´s dans le domaine de l'intelligence artificielle, car il constitue une fondation assez naturelle pour construire des systû´mes multiagents (les fameuses sociûˋtûˋs de fourmis en intelligence artificielle).
IV-D-4. Objets synchronisûˋs▲
L'association de la synchronisation û la transmission de messages, c'est-û -dire û l'invocation, offre l'avantage de traiter de maniû´re transparente une bonne partie de la synchronisation nûˋcessaire pour assurer une sûˋmantique correcte d'un programme rûˋparti. On peut distinguer trois niveaux de synchronisation correspondant respectivement û la concurrence interne d'un objet, û son interface, et û la coordination entre plusieurs objets. Dans le premier cas (synchronisation intraobjet), on exprime les restrictions en termes d'exclusions entre opûˋrations. Par exemple, des lecteurs peuvent lire simultanûˋment un mûˆme livre. Par contre, l'accû´s en ûˋcriture par un ûˋcrivain exclut tous les autres (ûˋcrivains comme lecteurs). Au 2e niveau (synchronisation comportementale), il se peut qu'un objet ne puisse temporairement traiter certains types de requûˆtes qui font pourtant partie de son interface. Par exemple, un tampon de taille bornûˋe ne pourra accepter une requûˆte d'insertion tant qu'il est plein. PlutûÇt que de signaler une erreur, il est en gûˋnûˋral plus judicieux de laisser en attente une telle requûˆte tant que la condition n'est pas remplie. Enfin, au 3e niveau (synchronisation interobjets), on peut dûˋsirer assurer une cohûˋrence, non plus seulement individuelle, mais globale entre de multiples objets. Prenons l'exemple d'un transfert de fonds entre deux comptes bancaires. En l'occurrence, on veut assurer l'atomicitûˋ, au sens transactionnel, du transfert, entre les deux objets comptes bancaires. La synchronisation intraobjet ou comportementale n'est alors plus suffisante. On introduit une synchronisation qui met en éuvre les deux objets reprûˋsentant les comptes bancaires.
V. Ils eurent beaucoup d'enfants▲
Le mariage des concepts d'objet et de rûˋpartition a donnûˋ naissance û un nombre impressionnant de langages, de systû´mes et de bibliothû´ques d'objets rûˋpartis. û ma connaissance, tous les projets actuels d'architectures rûˋparties sont basûˋs sur le concept d'objet. D'une part, les chercheurs issus de la communautûˋ langage de programmation û objets ûˋtendent les environnements de programmation vers des architectures rûˋparties, et d'autre part, les chercheurs issus de la communautûˋ systû´me adoptent le modû´le objet pour structurer les concepts de la rûˋpartition.
La notion d'encapsulation, fondamentale d'un point de vue conceptuel, devient tout aussi fondamentale d'un point de vue pratique. Si une sociûˋtûˋ informatique vend û travers le rûˋseau un service sous forme d'un objet invocable (e.g., un serveur Web), il est important pour cette sociûˋtûˋ que les utilisateurs ne puissent pas connaûÛtre la mise en éuvre du service (ils pourraient se rendre compte qu'ils ont payûˋ trop cher), et que les fonctionnalitûˋs du service soient les mûˆmes que celles d'une sociûˋtûˋ concurrente, mûˆme si les deux utilisent des mises en éuvre diffûˋrentes, des langages de programmation diffûˋrents et des systû´mes d'exploitation diffûˋrents.
Bien que certains dûˋveloppements universitaires associent les objets et la rûˋpartition suivant une approche particuliû´re (intûˋgrûˋe ou appliquûˋe), la grande majoritûˋ des systû´mes û objets rûˋpartis, et en particulier les produits commerciaux, font une synthû´se pragmatique des deux approches. Parmi les rejetons du couple objet et rûˋpartition, les plus connus ont pour noms CORBA, DCOM, Java (Java RMI) ou encore ONE.
V-A. CORBA▲
Depuis 1989, une association internationale appelûˋe l'OMG (Object Management Group) dûˋfinit la spûˋcification de l'architecture d'un systû´me û objets rûˋpartis, appelûˋe CORBA (Common Object Request Broker Architecture). Prû´s de 700 sociûˋtûˋs sont actuellement membres de l'OMG, aussi bien des sociûˋtûˋs informatiques comme HP, Digital, Sun, Microsoft, ou IBM, que des utilisateurs comme Boeing ou Alcatel. û l'inverse d'ODP (Open Distributed Processing), un autre effort de standardisation d'architectures rûˋparties, CORBA a ûˋtûˋ dûˋfini dans un but trû´s pratique, et de nombreuses mises en éuvre de la spûˋcification CORBA sont actuellement sur le marchûˋ, incluant SOM de IBM, ObjectBroker de Digital, Orbix de Iona, et Visibroker de Visigenic.
CORBA associe les concepts d'objet et de rûˋpartition dans une approche û la fois intûˋgrûˋe et appliquûˋe. L'intûˋgration se fait û travers la notion d'invocation û distance d'objet (l'objet est l'unitûˋ de rûˋpartition), et l'application se fait û travers les services de rûˋpartition qui sont organisûˋs sous forme de bibliothû´ques de classes.
Les objets CORBA, dont les interfaces sont dûˋcrites dans un langage spûˋcifique, nommûˋ IDL (Interface Description Language), sont portables sur diffûˋrents systû´mes d'exploitation, et des objets d'une mûˆme application peuvent ûˆtre ûˋcrits dans diffûˋrents langages de programmation. Avec la spûˋcification CORBA 2.0, et l'adoption du standard de communication IIOP (Internet InterORB Protocol), ces objets peuvent communiquer û partir de diffûˋrentes mises en éuvre de CORBA. Cela rûˋpond û l'un des soucis majeurs de l'informatique de cette dûˋcennie, û savoir l'intûˋgration de composants informatiques hûˋtûˋrogû´nes. Dans CORBA, le modû´le objet est appliquûˋ û tous les niveaux d'une application. Et en particulier, tous les services de rûˋpartition, comme le nommage, les transactions ou la persistance, sont spûˋcifiûˋs et mis en éuvre sous forme de classes d'objets CORBA. La notion de service CORBA explique, en grande partie, le succû´s commercial de CORBA, car elle permet û divers dûˋveloppeurs de logiciels de contribuer û la mise en éuvre de CORBA et d'en tirer les bûˋnûˋfices. Des sociûˋtûˋs comme Oracle ou Ingres peuvent par exemple vendre leur technologie bases de donnûˋes sous forme d'un service de persistance CORBA, alors qu'une sociûˋtûˋ comme Transarc peut vendre un moniteur transactionnel sous la forme d'un service transactionnel CORBA.
V-B. DCOM▲
Bien que membre de l'OMG, Microsoft a dûˋveloppûˋ son propre standard d'objets rûˋpartis, appelûˋ DCOM (Distributed Component Object Model). Le terme standard revûˆt dans ce contexte un caractû´re particulier, car il signifie standard pour, et seulement pour, les produits Microsoft.
L'histoire a commencûˋ en 1993 avec OLE 2.0 (Object Linking and Embedding), l'ensemble des mûˋcanismes permettant aux utilisateurs d'un produit Microsoft (e.g., PowerPoint) d'intûˋgrer des composants construits avec un autre produit Microsoft (e.g., des images Graph). Le fondement de OLE ûˋtait COM (Component Object Model), un standard de compatibilitûˋ binaire entre objets, et qui unifie l'architecture des diffûˋrents services OLE. Contrairement û CORBA, OLE n'a pas ûˋtûˋ crûˋûˋ û l'origine pour la programmation rûˋpartie. Depuis 1996 est apparu DCOM qui dûˋsigne les composants Windows qui peuvent ûˆtre distribuûˋs sur diffûˋrentes plates-formes (Windows) û travers Internet. Ces composants sont basûˋs sur une extension du modû´le objet COM aux environnements distribuûˋs, appelûˋ DCOM. L'usage initial des composants DCOM ûˋtait la mise en éuvre de documents composûˋs. Ici, la notion de document remplace la notion d'application dans CORBA. Un document est composûˋ de plusieurs composants rûˋpartis (tableaux, textes, graphiques).
On retrouve, comme dans CORBA, l'intûˋgration des concepts d'objet et de rûˋpartition, û la fois suivant une approche intûˋgrûˋe et appliquûˋe. L'approche intûˋgrûˋe se matûˋrialise par le fait que les objets sont des unitûˋs de rûˋpartition qui communiquent en utilisant des invocations û distance, et l'approche appliquûˋe par le fait de dûˋvelopper des services de rûˋpartition sous forme de bibliothû´ques de classes. Nûˋanmoins, û la diffûˋrence de CORBA, aucun mûˋcanisme ne permet de mettre en éuvre l'hûˋritage de classes. Ce mûˋcanisme est remplacûˋ par l'agrûˋgation (la composition d'objets) et la dûˋlûˋgation (un objet dûˋlû´gue û un autre objet ce qu'il ne sait pas faire).
V-C. Java, Java RMI et Java Beans▲
Aprû´s l'ûˋchec du projet initial OAK (premier nom du langage Java), visant û dûˋfinir un langage de programmation pour la tûˋlûˋvision interactive et les ûˋquipements de tûˋlûˋphonie, Sun Microsystems propulsa de nouveau Java sur le devant de la scû´ne en automne 1995, et suscita l'enthousiasme qu'on connaûÛt des utilisateurs et des programmeurs d'Internet en pleine expansion. Java ûˋlimine quelques aspects critiquables de C++ tels que les pointeurs et les templates, et introduit quelques aspects sympathiques de Smalltalk tels que le ramassage de miettes et une forme de manipulation (assez primitive) de classes en tant qu'objets. Les dûˋveloppements de Java et de ses bibliothû´ques sont dûˋsormais adoptûˋs par tous les logiciels visant Internet, y compris par Microsoft qui crûˋa Visual J++, une version de Java destinûˋe aux environnements Windows, sans pour autant renoncer au dûˋveloppement de DCOM, ni û sa participation û l'OMG.
Java intû´gre les objets et la rûˋpartition û travers le mûˋcanisme de migration. C'est le code qui se dûˋplaceô : il n'y pas, du moins dans les premiû´res versions des bibliothû´ques, d'invocation d'objet distant. Lorsqu'un fouineur comme Netscape charge une page Web et rencontre dans un code HTML (Hyper Text Markup Language) une ûˋtiquette dûˋsignant une applet Java (i.e., un programme Java qui peut se tûˋlûˋcharger û travers le Web), il retrouve le code de l'applet et le fait migrer vers le site client (en ûˋtablissant une connexion TCP/IP). La machine virtuelle Java du fouineur permet ensuite d'exûˋcuter le code Java (en fait le byte code) migrûˋ chez le client. Le fouineur efface ensuite le code de la mûˋmoire lorsqu'il quitte la page Web en question.
Plus rûˋcemment, JavaSoft, une filiale de Sun Microsystems, dûˋveloppa une bibliothû´que de classes, appelûˋe RMI (Remote Method Invocation), permettant la communication rûˋpartie, puis sous le nom de Java Beans (grains de cafûˋ Java), un ensemble d'outils d'introspection, de visualisation de programmes rûˋpartis, de persistance, et de gestion d'ûˋvûˋnements. On retrouve, en plus de la possibilitûˋ de migration initiale des objets Java, la possibilitûˋ d'invocation û distance d'objets ainsi qu'un ensemble de services rûˋpartis comme dans CORBA. û la diffûˋrence de CORBA, RMI prûˋsuppose que le client et le serveur sont dûˋveloppûˋs en Java, et que tous deux sont exûˋcutûˋs sur une machine virtuelle Java.
V-D. ONE▲
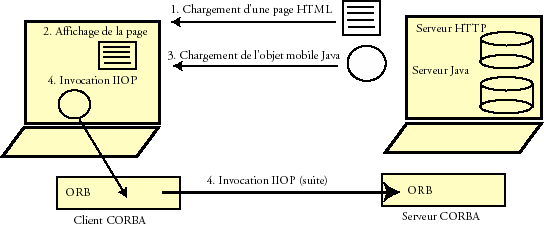
Netscape communications a prûˋsentûˋ en 1996 sa propre mise en éuvre de CORBA, en Java, baptisûˋe ONE (Open Network Environment). ONE offre la possibilitûˋ û une page Web tûˋlûˋchargûˋe û travers le fouineur Netscape de dialoguer ensuite avec un serveur CORBA. Une page Web peut ainsi contenir des objets CORBA (avec des interfaces IDL) qui peuvent û leur tour utiliser des objets (et des services) CORBA. La figure 3 prûˋsente les diffûˋrentes ûˋtapes mises en jeu. Tout d'abord, le navigateur tûˋlûˋcharge une page Web (1), l'affiche (2), puis tûˋlûˋcharge le code Java de l'applet (3). Ensuite, l'applet est localement exûˋcutûˋe et un objet CORBA est ensuite invoquûˋ û distance (4). Cet objet peut lui mûˆme invoquer d'autres objets, etc.
L'intûˋrûˆt de l'approche ONE est le subtil mûˋlange entre les avantages de Java et de CORBA, qui se traduit par la possibilitûˋ û la fois de migration des objets, et d'invocation û distance d'objets et de services (CORBA) hûˋtûˋrogû´nes. Une application peut ainsi avoir une partie applet Java tûˋlûˋchargeable û travers le Web, des parties serveur, utilisant des bases de donnûˋes (e.g., accûˋdant û Oracle û travers CORBA), ainsi que des composants dûˋveloppûˋs dans d'autres langages que Java (oui, il en existe encoreô !). De plus, le modû´le de programmation des objets CORBA est trû´s similaire û la programmation Java RMI. Le code IDL est directement gûˋnûˋrûˋ û partir du code Java. Par ailleurs, les objets sont rûˋfûˋrencûˋs par des adresses URL (comme n'importe quel document sur le Web). D'une certaine maniû´re, cela traduit l'ûˋvolution des objets rûˋpartis sur le Web (fig. 4).
VI. Et ils vûˋcurent heureuxô ? Non, et heureusement d'ailleursãÎ▲
Maintenant que la messe est dite, que le mariage entre les concepts d'objet et de rûˋpartition est consommûˋ, et que les fruits de ce mariage sont l'objet de toutes les convoitises par les grands industriels de l'informatique, on est en droit de se demander, en tant que chercheur universitaire, s'il est vraiment raisonnable d'entreprendre, ou mûˆme de continuer, des activitûˋs de recherche dans le domaine des objets rûˋpartis.
Une premiû´re rûˋponse consisterait û dire ô¨ô mais oui justement, cela permettrait d'avoir des contrats industriels plus facilement, et d'ûˆtre au courant des nouvelles technologies û enseigner aux ûˋtudiantsô ô£. D'une part, un laboratoire de recherche se retrouverait rapidement dans la situation d'intûˋgrer des technologies sans les maûÛtriser vraiment, ou d'agir comme sous-contractant ponctuel, moins cher que des sociûˋtûˋs de services informatiques. J'ai du mal û imaginer la qualitûˋ des thû´ses qui s'en suivraient. D'autre part, et sans aller jusqu'û l'attitude extrûˆme de ce grand professeur d'informatique amûˋricain qui aime û rûˋpûˋter ô¨ô je n'enseigne jamais ce que l'industrie rûˋclame, car ce qu'elle rûˋclame, elle l'enseignera elle-mûˆmeô ô£, il ne semble pas trû´s acadûˋmique de devoir modifier les manuels de cours au grûˋ des changements de stratûˋgies commerciales de Microsoft, IBM ou JavaSoft. Je viens d'apprendre par exemple que Microsoft vient de choisir comme nom pour son architecture rûˋpartie l'acronyme DNA (Distributed InterNet Applications).
VI-A. û la recherche d'abstractions standards▲
Comme mentionnûˋ prûˋcûˋdemment, la premiû´re maniû´re d'unir les concepts d'objet et de rûˋpartition consiste, suivant une approche appliquûˋe, û dûˋcomposer un systû´me rûˋparti en bibliothû´ques de classes.
Bien que des tentatives soient entreprises dans ce sens, il est encore beaucoup trop tûÇt pour considûˋrer qu'il existe une bibliothû´que de classes susceptible de devenir un standard pour la programmation rûˋpartie. Dans un contexte sûˋquentiel, il existe effectivement des abstractions fondamentales, telles que le tableau ou l'enregistrement. Dans un contexte concurrent, le sûˋmaphore est lui aussi devenu une abstraction fondamentale qui fait dûˋsormais partie de la plupart des bibliothû´ques de programmation concurrente. Dans un contexte rûˋparti, aucune abstraction fondamentale ne se dûˋgage vraiment. Cela souligne le fait que le domaine de la programmation rûˋpartie est relativement nouveau et assez complexe. Cela est d'autant plus vrai lorsqu'on considû´re des problû´mes de tolûˋrance aux dûˋfaillances ou des contraintes temporelles.
Les difficultûˋs d'un tel exercice (i.e., trouver et organiser des abstractions adûˋquates) rûˋsident d'une part dans une bonne comprûˋhension des mûˋcanismes minimaux de la programmation rûˋpartie, et d'autre part dans un consensus sur ces mûˋcanismes. Un tel consensus devrait mettre en jeu diffûˋrentes communautûˋs de chercheursô : langages, rûˋpartition, et parfois bases de donnûˋes (pour des mûˋcanismes transactionnels par exemple).
VI-B. L'intûˋgration ne se fait pas toujours sans dûˋgûÂt▲
Certains mûˋcanismes dûˋveloppûˋs par la programmation par objets ont ûˋtûˋ fondûˋs sur des hypothû´ses fortes d'informatique traditionnelle, c'est-û -dire sûˋquentialitûˋ de l'exûˋcution des programmes et espace mûˋmoire unique. Ils peuvent ainsi atteindre leurs limites quand ils sont transposûˋs directement dans l'univers de la programmation rûˋpartie, suivant l'approche applicative, oû¿ ils sont fusionnûˋs avec des concepts de la rûˋpartition.
Particuliû´rement significatif est le cas du mûˋcanisme d'hûˋritage par exemple. La premiû´re limitation tient û la volontûˋ d'appliquer le concept d'hûˋritage û la spûˋcialisation d'un nouvel aspect des objetsô : la synchronisation. Il se peut que dans certains cas la dûˋfinition d'une sous-classe, rajoutant une seule mûˋthode û la classe parente, impose la redûˋfinition de l'ensemble des spûˋcifications de synchronisation, annulant ainsi le premier bûˋnûˋfice de l'hûˋritageô : la rûˋutilisabilitûˋ du code. Par ailleurs, la mise en éuvre de l'hûˋritage dans un systû´me rûˋparti pose le problû´me de l'accû´s distant au code des classes parentes, û moins que celles-ci ne soient dupliquûˋes sur toutes les machines, avec les coû£ts consûˋquents. De nombreux articles ont ûˋtûˋ ûˋcrits sur le sujet, qui reste nûˋanmoins trû´s ouvert.
La deuxiû´me limitation tient cette fois aux hypothû´ses fortes des techniques de mise en éuvre des classes, et en particulier des variables de classe, ce qui limite leur transposition immûˋdiate û un univers rûˋparti. Il semble difficile, û moins d'introduire des mûˋcanismes transactionnels compliquûˋs, de garantir que la mise û jour d'une variable de classe soit immûˋdiatement reflûˋtûˋe sur toutes les instances d'une classe, lorsque celles-ci sont situûˋes sur plusieurs machines. Ce problû´me se pose pour des variables globales en gûˋnûˋral, mais est accentuûˋ dans les langages û objets, car des variables de classes sont souvent implicitement utilisûˋes par le programmeur, qui ne se rend pas toujours compte que ce sont des variables globales dont la mise en éuvre est trû´s coû£teuse dans un contexte rûˋparti.
Enfin, la troisiû´me limitation est relative û la notion de duplication, particuliû´rement utile pour tolûˋrer les dûˋfaillances. Si elle est appliquûˋe directement aux objets, la duplication provoque des incohûˋrences d'exûˋcution. Les protocoles de communication dûˋfinis pour contrûÇler la duplication des services dans un systû´me rûˋparti considû´rent un modû´le client/serveur simple. L'application des mûˆmes protocoles aux objets pose le problû´me de la duplication des invocations. En effet, un objet agit gûˋnûˋralement û la fois comme un client et un serveur. Autrement dit, s'il est dupliquûˋ en tant que serveur, l'objet peut û son tour invoquer d'autres objets en tant que clients. Toutes les copies de l'objet invoqueront alors le mûˆme objet plusieurs fois. Le rûˋsultat est la duplication inutile des invocations. Cette duplication peut conduire au meilleur des cas û l'inefficacitûˋ du systû´me, et au pire des cas û des incohûˋrences. Une mûˆme opûˋration (par exemple d'incrûˋmentation) peut ainsi ûˆtre exûˋcutûˋe plusieurs fois plutûÇt qu'une.
VI-C. Vers une troisiû´me approche complûˋmentaire▲
L'approche appliquûˋe permet d'offrir au programmeur de systû´mes des mûˋcanismes ou/et des concepts pour gûˋrer la rûˋpartition. Les concepts de gûˋnûˋricitûˋ et de classe permettent de structurer ces mûˋcanismes et concepts en une vûˋritable palette de mûˋcanismes et de solutions. Cependant, plus encore qu'une palette de solutions, il est judicieux de permettre une extensibilitûˋ plus gûˋnûˋrale, c'est-û -dire d'offrir une mûˋthodologie et des moyens lui permettant d'exprimer et de construire des solutions spûˋcifiques si nûˋcessaire, sans pour cela modifier l'application prûˋalablement dûˋveloppûˋe, c'est-û -dire de maniû´re transparente û l'application.
L'approche intûˋgrûˋe offre cette transparence en fusionnant les concepts d'objet et de rûˋpartition. Nûˋanmoins, les systû´mes intûˋgrûˋs peuvent fixer trop tûÇt leurs modû´les d'exûˋcution et de communication. Le langage de programmation dûˋlû´gue alors la gestion des ressources, telles que le placement des objets et le sûˋquencement des tûÂches sur chaque processeur, au systû´me d'exûˋcution sous-jacent. La sûˋmantique du systû´me est sinon prûˋcûÂblûˋe, du moins non modifiable au niveau du langage lui-mûˆme. Mûˆme si le langage offre des facilitûˋs de changement des caractûˋristiques du modû´le de calcul, et de gestion des ressources, le programme devient alors moins lisible et surtout moins rûˋutilisable, du fait du mûˋlange du texte du programme mûˆme, avec les portions spûˋcifiant le contrûÇle.
Une troisiû´me approche se dûˋgage pour combler ces lacunes: l'approche rûˋflexive. Elle a pour objectif de faire apparaûÛtre, au niveau du langage de programmation, diverses caractûˋristiques de reprûˋsentation (statiques) et d'exûˋcution (dynamiques) du programme. Ces caractûˋristiques sont dûˋcrites et modifiables par l'intermûˋdiaire d'un mûˋtaprogramme. La rûˋflexion est une version de la mûˋtaprogrammation, oû¿ le mûˋtaprogramme est dûˋcrit dans le langage lui-mûˆme. Ceci offre ainsi l'avantage d'une approche plus homogû´ne, le mûˆme langage ûˋtant employûˋ, pour l'ûˋcriture des programmes, comme pour leur contrûÇle. L'approche rûˋflexive est, en quelque sorte, un moyen terme entre l'approche intûˋgrûˋe et l'approche appliquûˋe, car elle permet d'intûˋgrer intimement les (mûˋta) bibliothû´ques avec le langage, tout en les sûˋparant du programme. De nombreuses architectures rûˋflexives sont actuellement proposûˋes et ûˋvaluûˋes, mais il est trop tûÇt pour dûˋgager, et valider, une architecture rûˋflexive gûˋnûˋrale pour la programmation rûˋpartie. Un des problû´mes est la complexitûˋ ûˋventuelle des architectures rûˋflexives, qui est en partie liûˋe aux possibilitûˋs accrues de paramûˋtrisation qu'elles offrent. Un autre problû´me est celui de l'efficacitûˋ, du fait des indirections et interprûˋtations supplûˋmentaires que la rûˋflexion peut entraûÛner. L'ûˋvaluation partielle est actuellement proposûˋe comme une des techniques permettant de rûˋduire ces surcoû£ts. Les notions de filters ou de smart proxies dans certaines mises en éuvre de CORBA peuvent ûˆtre vues comme un premier pas d'une approche rûˋflexive pragmatique dans l'industrie.
VII. Pour en savoir plus▲
Sur les recherches dans le domaine des objets rûˋpartis, de bonnes sources d'informations sont les actes des confûˋrences OOPSLA (International Conference on Object Oriented Programming Systems, Languages, and Applications), publiûˋs par l'ACM dans la collection Sigplan, et les actes de la confûˋrence ECOOP (European Conference on Object Oriented Programming), publiûˋs par Springer Verlag dans la collection Lecture Notes in Computer Science. Pour en savoir plus sur les produits commerciaux, il suffit de demander û votre moteur de recherche prûˋfûˋrûˋ sur le Web de trouver Java RMI, ONE, CORBA, ou DCOM.
VIII. L'auteur▲
L'auteur Rachid Guerraoui est Professeur associûˋ au Laboratoire de programmation distribuûˋe û l'ûcole Polytechnique Fûˋdûˋrale de Lausanne.